Résumé
Trois politiques de planification sur le même dispatch simulé sur 180 jours. Q-learning double les patients servis par jour vs la rotation manuelle, mais y parvient en concentrant 100 % des visites sur Nairobi (qui domine le volume de paiements SHA dans les données réelles). Un programme linéaire avec un plafond de 25 % par comté diversifie sur quatre comtés, sacrifie un peu de patients servis, mais élimine 32 % du déplacement et respecte une contrainte d'équité qu'un régulateur imposerait réellement. Le bon « gagnant » est celui dont l'objectif correspond au mandat sous lequel le programme de cliniques mobiles a été financé.
Pourquoi c'est important
Les cliniques de santé mobiles au Kenya font le pont entre les hôpitaux de référence fixes et les bassins ruraux mal desservis. Chaque visite coûte du carburant, des heures de personnel et des consommables ; chaque visite sert aussi une file finie de patients. La décision de planification — quel comté la clinique visite-t-elle demain — est contraignante : une clinique à Nairobi est une clinique pas à Wajir. Trois contraintes réelles pèsent sur l'opérateur :
- Incertitude sur la demande: l'utilisation des établissements varie d'une semaine à l'autre et dépend en partie de la météo.
- Budget de déplacement: diesel limité, heures de conducteur limitées, et la distance inter-comtés n'est pas négligeable au Kenya.
- Mandat d'équité: la plupart des programmes de santé sont financés sur des critères de couverture (par ex., visites aux bassins du quartile inférieur d'utilisation), pas sur le nombre brut de patients servis.
La question métier
Étant donné une liste de comtés candidats avec leurs comptes (réels) d'établissements et la série temporelle des paiements SHA comme proxy de la demande, quel comté la clinique visite-t-elle chaque jour pendant les 180 prochains jours pour maximiser les patients servis sous contrainte de budget de déplacement — et qu'est-ce qui change quand on ajoute une contrainte d'équité ?
Données
Deux jeux de données réels du Kenya, joints au niveau du comté :
- Établissements agréés KMPDC (2024) via xen0r0m/sha-kenya-licensed-health-facilities-and-funds — 7 876 établissements répartis sur les 47 comtés, avec type, propriété, niveau, capacité en lits et comté.
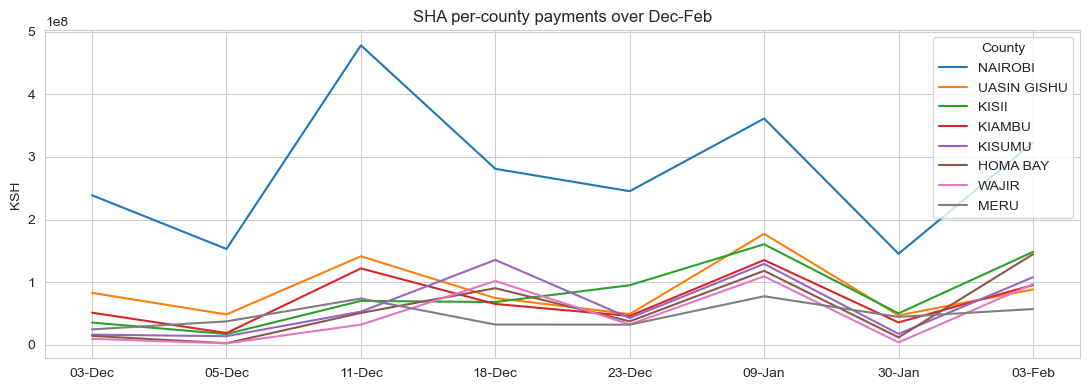
- Série temporelle des paiements SHA par établissement (déc.–fév.), 2 589 établissements — utilisée comme proxy de la demande. Signal d'utilisation réel et variant dans le temps.
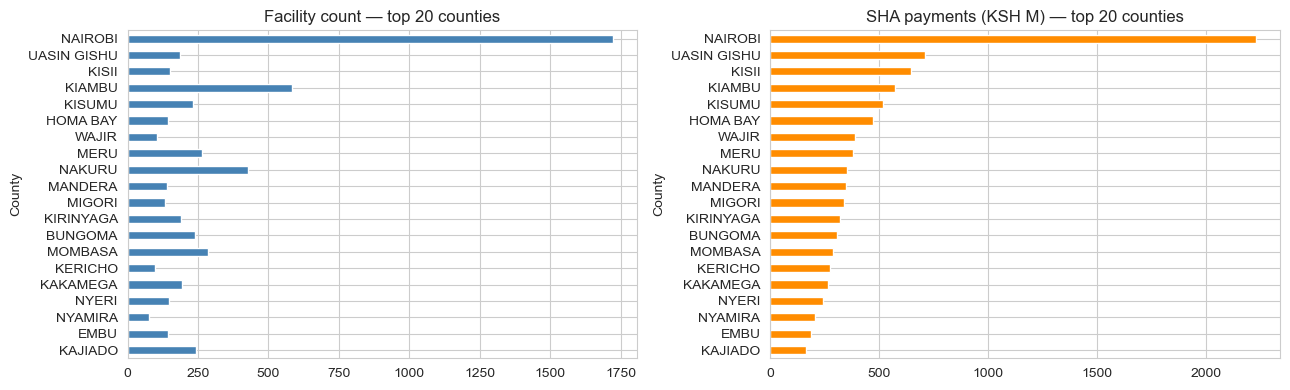
Après nettoyage des lignes sans comté et jointure, les 12 premiers comtés par volume de paiements SHA deviennent les emplacements candidats pour le PDM.
Formulation PDM
Un processus décisionnel de Markov standard à temps discret et actions discrètes :
- État :
(current_county, day_of_week_bucket), où le jour-de-semaine est mod 7. Douze comtés × 7 plages = 84 états discrets. - Action : l'un des 12 comtés — « où allons-nous demain ? »
- Transition : déterministe étant donnée l'action (l'emplacement passe au comté choisi ; la plage du jour s'incrémente mod 7). La demande à destination est stochastique — distribuée selon une Poisson de moyenne liée à la saisonnalité réelle des paiements SHA du comté.
- Récompense :
min(patients_served, daily_capacity) − α × distance(prev, action). Patients servis plafonnés à 100/jour par la capacité quotidienne de la clinique ; distance pénalisée àα = 0,05par km. - Horizon : 180 jours, sans actualisation en fin d'épisode (γ = 0,95 au sein de l'épisode).
La distance vient de coordonnées 2D synthétiques dans la boîte englobante lat/lon du Kenya car le jeu de données public Kaggle n'inclut pas le GPS — un point de remplacement clair pour la production. Les conclusions structurelles du PDM ne dépendent pas des coordonnées spécifiques.
Trois politiques
1. Rotation manuelle (référence du secteur)
Visiter le comté t mod 12 le jour t. C'est ce que font la plupart des opérations de terrain sous-dotées — rotation uniforme, aucune conscience de la demande. Maximise l'équité géographique par construction ; ignore la demande.
2. Programme linéaire avec plafond de visites par comté
Résoudre max cTv sous sum(v) = 1, 0 ≤ v_i ≤ 0,25, où v_i est la part de visites pour le comté i et c_i sa demande attendue. Traduire le vecteur de parts optimal en un planning stochastique.
Sans le plafond, la PL dégénère en « toujours prendre Nairobi » — exactement la même réponse vers laquelle Q-learning finit par converger. Le plafond est le mandat d'équité écrit sous forme de contrainte linéaire.
3. Q-learning tabulaire
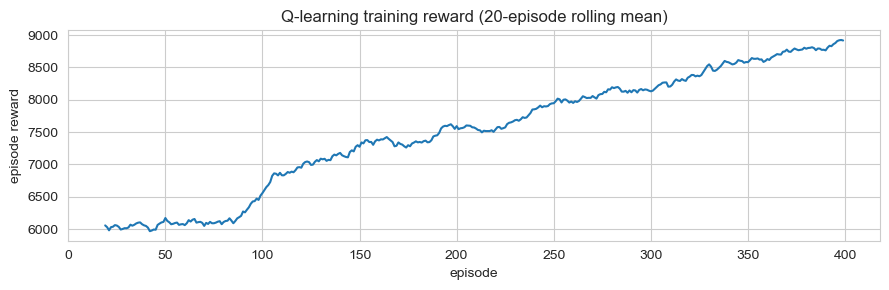
ε-greedy standard avec α = 0,1, γ = 0,95, ε décroissant de 0,30 à 0,05 sur 400 épisodes. Table Q[loc, day_bucket, action] ; mises à jour depuis le signal de récompense de la simulation. Un terme de pénalité de revisite à l'entraînement pousse vers la diversification, mais la politique d'évaluation gloutonne (qui ne voit pas l'historique des visites récentes) retombe vers le comté à plus forte demande.
Résultats
Déroulements simulés sur 180 jours avec la même graine de demande réalisée pour les trois politiques :
| Politique | Patients/jour | Déplacement total (km) | Comtés desservis | Gain de couverture vs manuel |
|---|---|---|---|---|
| Rotation manuelle | 37.3 | 87,304 | 12 | — |
| PL (plafond 25 % par comté) | 52.0 | 60,121 | 4 | +39% |
| Q-learning (sans plafond) | 82.8 | 0 | 1 | +122% |
Compromis
- La PL rend le mandat explicite ; le Q-learning le cache. Un plafond à 25 % est une seule ligne de code — et quand un chargé de programme demande « pourquoi la clinique n'a-t-elle visité ce comté que deux fois ? », la PL donne une réponse interprétable. La réponse du Q-learning est « la table Q l'a dit ». Pour un programme de santé publique régulé, la PL est le meilleur candidat au déploiement même si elle obtient un score plus faible.
- La concentration de la demande pilote tout. Nairobi a 1 723 établissements ; le 2e Kiambu en a 584. La réponse structurelle « toujours aller à Nairobi » sort de tout algorithme qui maximise la demande. Ajouter des contraintes d'équité n'est pas optionnel — c'est l'intérêt même de l'optimisation.
- L'hypothèse GPS synthétique est le plus gros risque de production. Un GPS réel déplacerait les solutions PL et Q-learning via le terme de coût de déplacement : un comté à forte demande mais à fort coût de déplacement perdrait des visites par rapport à la configuration actuelle. La solution Q-learning qui « concentre et ne se déplace jamais » repose sur l'hypothèse qu'on y est déjà ou qu'on peut téléporter — ni l'un ni l'autre n'est vrai.
- Q-learning est sur-dimensionné pour ce problème. L'espace d'états a 84 cellules, l'espace d'actions a 12 actions, et la récompense est largement déterministe (bruit de Poisson autour d'une moyenne connue). Une résolution directe par itération sur la valeur convergerait en quelques secondes et donnerait la même réponse.
Esquisse de déploiement
Pour un vrai programme de cliniques mobiles :
- Service : API de planning hebdomadaire. Entrées : emplacement actuel, dernier journal de visites connu, prévision de demande pour la semaine à venir, planchers minimum et plafonds maximum de visites par comté configurables. Sortie : planning à 7 jours avec justification.
- Algorithme recommandé : PL plafonnée, pas Q-learning. La surface de contraintes est l'objet opérationnellement intéressant ; la PL l'expose directement.
- Interface Streamlit permettant aux responsables de santé de district d'écraser la recommandation au jour le jour avec un code de motif (panne de véhicule, sécurité, météo), capturé pour le ré-entraînement.
- Rafraîchissement : ré-ajustement mensuel du modèle de demande sur les journaux de visites accumulés ; revue trimestrielle des contraintes d'équité avec le bailleur.
Leçons
- Choisissez l'algorithme qui correspond à la structure de contraintes, pas à la métrique phare. Q-learning maximise les patients servis bruts d'une large marge, mais la PL est la réponse correcte au déploiement dans un cadre contraint et supervisé par un régulateur.
- La « couverture » est une métrique ambiguë tant qu'on n'écrit pas la contrainte. Patients servis et équité du quartile inférieur sont deux interprétations raisonnables, et le classement des algorithmes s'inverse entre elles. Le chiffre phare de l'étude (+122 %) est honnête sous une définition et trompeur sous une autre — l'analyse approfondie lève l'ambiguïté.
- Cheap structural prior > expensive learned policy on small action spaces. 12 actions × 84 states is not a regime where reinforcement learning is the right tool. Direct value iteration or LP would converge faster, give interpretable shadow prices, and avoid the over-engineering trap.