Résumé
Sur le jeu de données canonique freMTPL2 de responsabilité civile auto français, un GLM Tweedie Poisson-composé bat à la fois un GLM Poisson + Gamma ajusté séparément et un concurrent gradient boosté sur la métrique de segmentation standard (coefficient de Gini sur la prime pure par police). Mais Poisson + Gamma gagne sur une autre métrique opérationnellement pertinente — le lift du décile supérieur — et reste le choix le plus défendable lorsque les déterminants de la fréquence et de la gravité divergent. Le « bon » modèle de tarification est celui dont les biais correspondent à la façon dont le moteur de tarification et l'équipe de souscription utiliseront effectivement le score.
La question métier
Un assureur auto veut des estimations de pertes attendues par police: la prime pure — assez précises pour alimenter un moteur de tarification par paliers et assez explicables pour validation actuarielle. Deux usages opérationnels reposent sur le score :
- Tarification. Chaque police a besoin d'un montant qui, en espérance, couvre ses sinistres plus une marge. Les erreurs se traduisent directement par un profit (ou une perte) de souscription.
- Segmentation. L'équipe actuarielle veut identifier et tarifer correctement le décile le plus risqué, où se concentre l'essentiel des sinistres.
Un GLM Poisson historique était déjà en production (standard du secteur). La question : Tweedie ou un concurrent ML pourrait-il améliorer significativement l'une ou l'autre dimension ?
Données
Vrai freMTPL2 de la Fédération française des sociétés d'assurances, redistribué via Kaggle sous floser/french-motor-claims-datasets-fremtpl2freq (sinistres) et floser/fremtpl2sev (gravités). Après jointure et plafonnement des gravités au 99,9e percentile (pratique standard pour limiter la distorsion des sinistres catastrophiques) :
- 678 013 polices, ~5 % ont eu au moins un sinistre pendant leur fenêtre d'exposition.
- Taux moyen de fréquence ~0,10 sinistre/an/police ; gravité moyenne des sinistres positifs ~1 500 EUR.
- Covariables :
exposure,area,veh_power,veh_age,driv_age,bonus_malus,veh_brand,veh_gas,density,region.
EDA & surdispersion
Deux faits empiriques dominent la décision de modélisation :
- La distribution du nombre de sinistres est très concentrée sur zéro. Près de 95 % des polices ne déclarent aucun sinistre. Parmi celles qui le font, la plupart en déclarent exactement un — la queue lourde des deux-ou-plus est réellement petite.
- La gravité a une queue droite épaisse. La plupart des sinistres positifs sont modestes (~1 000 EUR), mais une longue queue s'étend jusqu'au plafond par police. Modéliser la gravité en espace linéaire sans lien logarithmique est exclu.
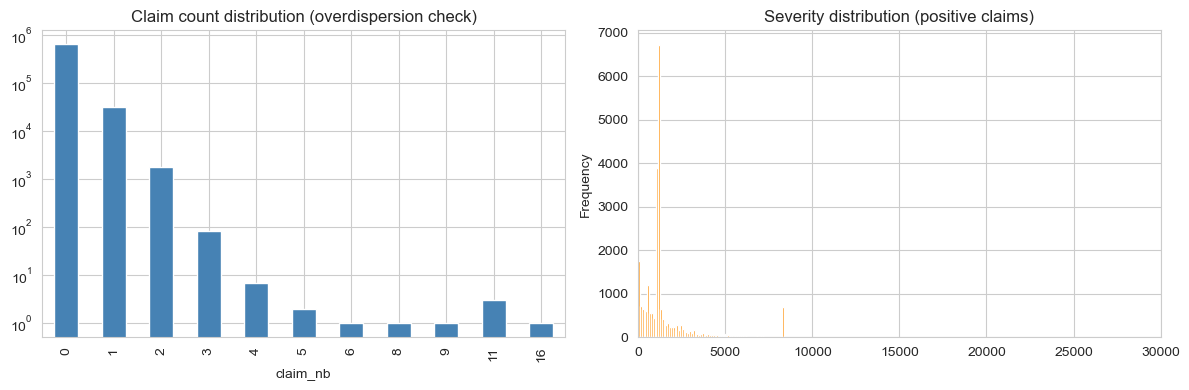
Le ratio variance/moyenne empirique du nombre de sinistres est de 1,083. Surdispersion légère — Poisson est une référence défendable, mais une famille binomiale négative ou Tweedie capture la variance supplémentaire plus proprement.
Approche de modélisation
Trois familles de modélisation sur le même découpage 80/20. Toutes entraînées avec offset = log(exposure) pour la fréquence, et la gravité restreinte aux sinistres positifs. Les prédictions de prime pure sont produites sur l'ensemble de test en combinant fréquence et gravité quand elles vivent dans des modèles séparés, ou directement quand elles ne le font pas.
1. GLM Poisson + Gamma (référence du secteur)
La décomposition actuarielle classique : modéliser la fréquence des sinistres avec un Poisson GLM (lien log, offset d'exposition) et la gravité conditionnelle avec un Gamma GLM sur les sinistres positifs. Prime pure = E[N|X] / exposure × E[Y|X, N≥1]. Facile à interpréter coefficient par coefficient ; facile à consommer pour le moteur de tarification ; facile à expliquer à un régulateur.
2. GLM Tweedie Poisson-composé
Un seul modèle sur la cible « prime pure par unité d'exposition » avec une distribution Tweedie(var_power=1.5) et lien log. Gère l'inflation de zéros et la queue positive en un seul ajustement. Expose une histoire plus propre : un seul jeu de coefficients sur la même réponse. Le compromis est que fréquence et gravité ne sont plus modélisées séparément, donc un coefficient ne peut plus se décomposer en « ce conducteur a plus de chances de déclarer » vs. « ce conducteur déclare des sinistres plus gros ».
3. Régression gradient boostée (concurrent)
Une paire de modèles GradientBoostingRegressor: un sur la fréquence par unité d'exposition, un sur la log-gravité — multipliés pour donner la prime pure. Aucune contrainte de monotonie (un système de production en ajouterait sur bonus_malus), aucun prior d'interaction. L'objectif est de voir ce que la famille de méthodes capte que les GLM ratent.
Résultats
Validation 80/20. Deux métriques :
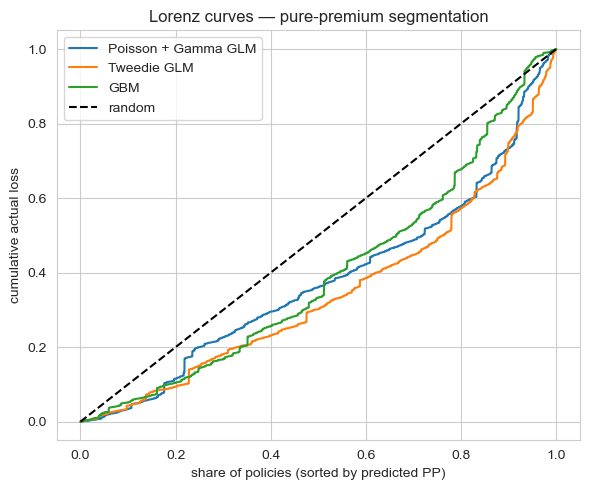
- Coefficient de Gini sur la prime pure: mesure de la qualité de l'ordonnancement des polices par sinistralité réalisée. Plus haut = meilleure segmentation.
- Lift du décile supérieur: parmi les 10 % de polices que le modèle juge les plus risquées, quel est le multiple de sinistralité réalisée par rapport à la moyenne de la population ? Plus haut = capture de risque plus concentrée dans le palier le plus élevé.
| Modèle | Gini (PP) | Lift décile sup. |
|---|---|---|
| GLM Tweedie (var_power = 1,5) | 0.310 | 2.52 |
| GLM Poisson + Gamma | 0.241 | 2.66 |
| GBM (Poisson + Gamma) | 0.211 | 1.45 |
Compromis
- L'histoire des coefficients de Tweedie est unifiée mais moins granulaire. Chaque coefficient affecte directement la prime pure ; vous perdez l'habitude actuarielle de décomposer un changement de palier en « plus de sinistres » vs. « sinistres plus gros ». Si votre équipe pense ainsi, Poisson + Gamma reste plus clair.
- Poisson + Gamma compose deux erreurs de modèle. Prime pure = fréquence × gravité, donc tout biais sur l'un se propage. Tweedie contourne cela en ajustant conjointement.
- Le GBM est le plus faible des trois sur ces données. Sans contraintes de monotonie, il est aussi le plus difficile à défendre — une version production en ajouterait sur
bonus_maluset peut-êtredriv_age, et fermerait probablement la majeure partie de l'écart de Gini. Conservé comme artefact de recherche, pas comme candidat de production. - Tous les trois sous-segmentent la queue la plus lourde. Un jeu de données à 5 % de taux de sinistre récompense les modèles capables de trouver les polices à sinistres rares ; même le Gini de 0,31 de Tweedie signifie que le modèle est loin d'un ordonnancement parfait. C'est un plafond imposé par les variables, pas un plafond algorithmique — ajouter un signal de télématique ou un zonage géographique plus fin compterait davantage que changer de modèle.
Esquisse de déploiement
Pour le moteur de tarification et l'équipe actuarielle :
- Artefact de scoring. Exporter les coefficients Tweedie en CSV, plus le GBM en modèle picklé. Le moteur de tarification évalue les deux et renvoie la prédiction gagnante (configurable) ; un emplacement de test A/B permet à l'équipe de les comparer sur des cohortes en production.
- Note actuarielle. Graphiques de dépendance partielle pour chaque covariable (surtout
bonus_malusetdriv_age), tables de calibration regroupées par décile prédit, et courbes de Lorenz sur cohortes glissantes. - Surveillance de la dérive. Gini mensuel sur une cohorte de validation ; alerte si Gini tombe sous 0,25 sur une fenêtre de 60 jours. Réajustement complet annuel ; revue trimestrielle.
- Audit d'équité. Tables de calibration par décile d'âge conducteur et par région — signalées pour revue actuarielle dès que l'erreur de calibration sur la cohorte de test dépasse 5 %.
Leçons
- Choisissez la métrique que votre consommateur aval utilise réellement, puis choisissez le modèle. Tweedie gagne sur le Gini global ; Poisson + Gamma gagne sur le lift du décile supérieur. Si votre moteur de tarification segmente par paliers, la bonne réponse n'est pas le modèle au Gini le plus élevé.
- Une surdispersion légère ne rend pas Tweedie obligatoire. Var/Moy = 1,083 signifie que Poisson n'est pas mal spécifié. La victoire de Tweedie est réelle mais modeste ; le vrai différenciateur est l'adéquation à la philosophie de modélisation (un modèle vs. deux).
- Les GLM battent toujours le ML non contraint sur ce type de données. Sans priors de monotonie et régularisation des variables, un GBM est structurellement trop flexible pour le ratio signal/bruit de l'assurance auto. Le bon déploiement ML dans ce domaine est le boosting à contraintes monotones plus la calibration — la version non contrainte est un point de recherche, pas un gain de production.