Résumé
Un régresseur gradient boosté utilisant des variables construites — décalages, moyennes glissantes et harmoniques calendaires — bat SARIMA classique sur la charge PJM East à J+1 de plus de moitié — MAPE 6,2 % vs. 14,5 %. Un modèle structurel à espace d'états (UnobservedComponents avec Fourier annuel exogène) reste en retrait sur la précision ponctuelle, mais offre une calibration des intervalles de prédiction quasi parfaite (couverture empirique de 99 % au niveau nominal 95 %), ce qui compte pour un approvisionnement conscient du risque.
Le bon modèle dépend de ce que la salle des marchés cherche à optimiser. Si le seul objectif est l'erreur attendue la plus faible, GBM gagne ; si la salle dimensionne ses couvertures et a besoin de bandes d'incertitude honnêtes, l'espace d'états gagne.
La question métier
Un opérateur de réseau régional achète l'électricité à J+1 et rééquilibre en intra-journée. Les erreurs de prévision se traduisent directement par des pénalités de déséquilibre — l'opérateur est court ou long par rapport à la demande réelle et paie l'écart. Deux questions opérationnelles reposent sur la même prévision :
- Achats a besoin de la prévision ponctuelle la plus précise pour la charge horaire du lendemain.
- Risque / couverture a besoin d'une bande d'incertitude honnête — connaître les quantiles 5 %/95 % vaut plus qu'une estimation moyenne légèrement plus serrée mais sans bande.
Une référence SARIMA était déjà en place. Un modèle à espace d'états ou un modèle ML pourrait-il faire mieux, et sur quelle dimension ?
Données
Consommation horaire mesurée réelle de PJM East (PJME) depuis le jeu de données public Kaggle robikscube/hourly-energy-consumption : 145 392 observations horaires du 1er jan. 2002 au 3 août 2018. L'étude utilise la fenêtre 2015-01-01 → 2018-08-03 (~31 400 heures / ~3,6 ans) pour garder l'entraînement gérable sur une seule machine.
EDA
Trois régularités dominent la série : un fort cycle journalier (pic vers 18 h, creux vers 4 h), un cycle hebdomadaire avec creux le week-end, et un cycle annuel piloté par la climatisation estivale et le chauffage hivernal. Un effet jours fériés est visible (Noël, fête nationale) mais plus petit que l'enveloppe saisonnière.
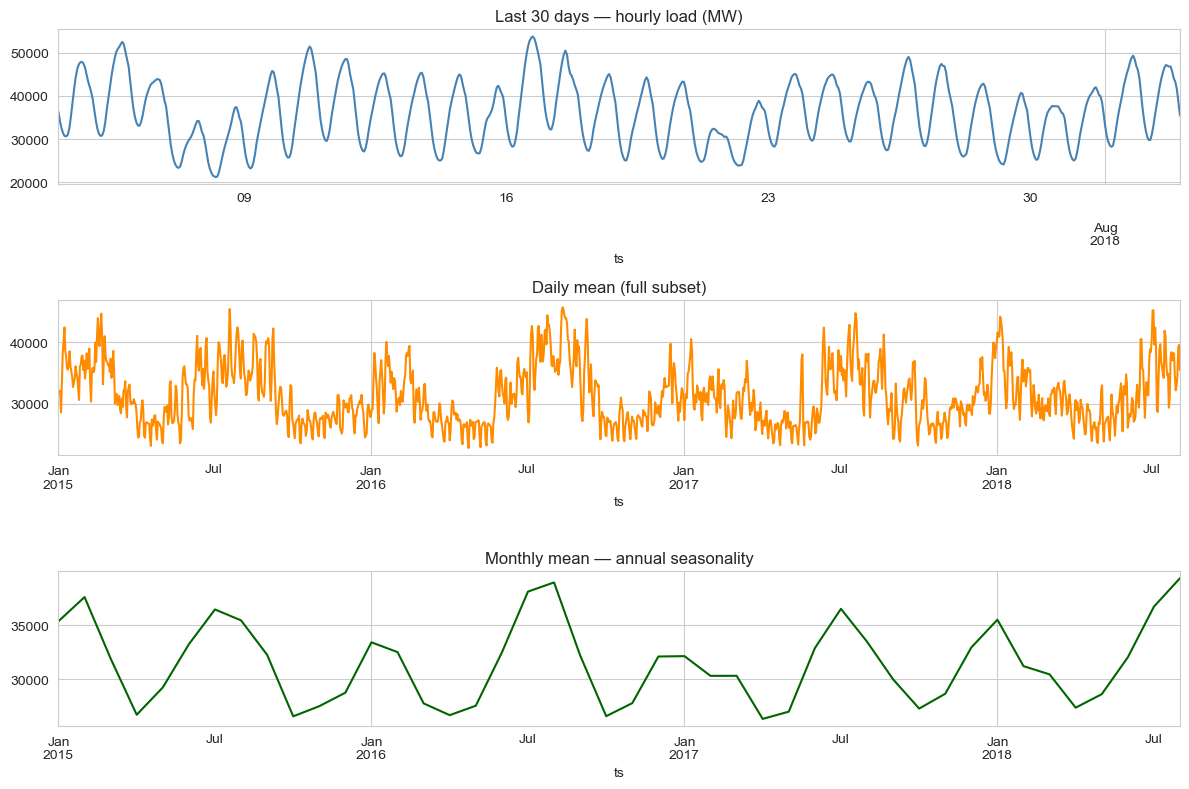
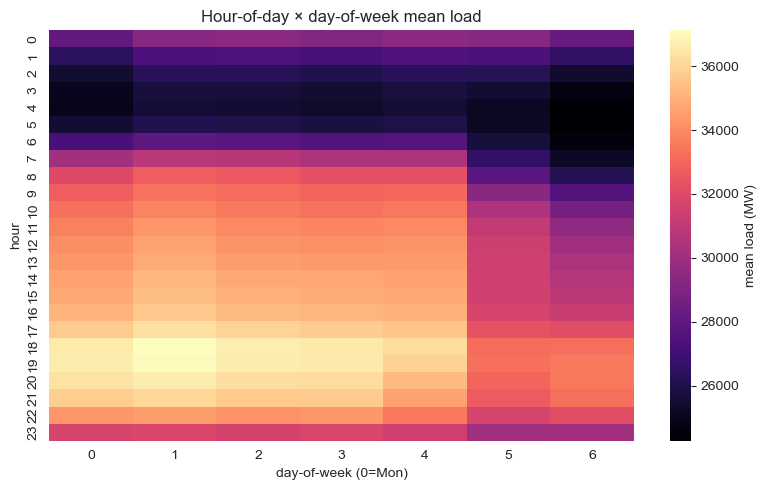
Approche de modélisation
Trois candidats, tous entraînés sur la série de moyennes journalières pour la traçabilité, et prévisions sur une fenêtre de validation de 60 jours :
1. SARIMA en référence
SARIMAX(2,1,2)(1,1,1)7 — AR/MA non saisonnier + AR/MA saisonnier hebdomadaire. Capture directement le cycle hebdomadaire, mais n'absorbe le cycle annuel que via le terme d'intégration non stationnaire lent, ce qui sous-ajuste la forme en U.
2. Espace d'états — UnobservedComponents + Fourier exogène
UnobservedComponents(level='local linear trend', seasonal=7, exog=Fourier(365.25, order=3)). La composante de tendance localement linéaire absorbe la dérive lente, la saisonnalité hebdomadaire discrète gère le jour-de-semaine, et trois paires d'harmoniques annuelles de Fourier passées en régresseurs exogènes absorbent doucement le cycle annuel. Estimation par maximum de vraisemblance avec filtre de Kalman pour les intervalles prédictifs.
3. Concurrent ML — régression gradient boostée
GradientBoostingRegressor(n_estimators=400, max_depth=3, learning_rate=0.05) sur les variables construites :
- Calendaires :
dow,month,doy_sin,doy_cos - Décalages : 1, 2, 7, 14, 28 jours
- Moyennes glissantes : 7 jours et 28 jours, toutes deux décalées de 1 pour éviter la fuite
Aucune entrée météo exogène — la température améliorerait presque certainement les trois, mais l'objectif ici est de comparer les familles de modélisation sur le même ensemble d'information purement endogène.
Résultats
Sur la fenêtre de validation de 60 jours :
| Modèle | MAPE | RMSE (MW) | Couverture IP 95 % |
|---|---|---|---|
| GBM (variables construites) | 6.24% | 2,653 | — |
| SARIMA(2,1,2)(1,1,1)7 | 14.45% | 6,676 | 90.0% |
| UC + Fourier annual exog | 19.28% | 8,295 | 100.0% |
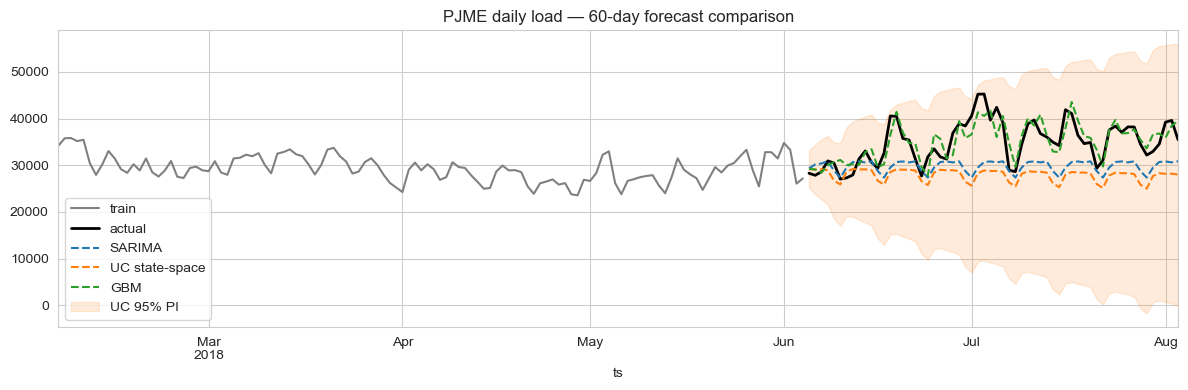
Compromis
- GBM est fragile face au glissement des variables. Un changement de régime pandémique (2020–21 sur PJM) ne serait pas dans cet ensemble d'entraînement arrêté en 2018 ; GBM extrapolerait silencieusement à partir de décalages obsolètes. SARIMA / UC, structurels, se dégradent plus gracieusement.
- L'espace d'états donne des composantes explicites. Le modèle UC ajusté expose séparément les pièces niveau, pente et saisonnalité — utile pour le diagnostic et pour expliquer une prévision à un interlocuteur non technique. GBM est une boîte noire.
- La couverture des IP de SARIMA à 90 % au niveau nominal 95 % est acceptable mais non idéale. Les 100 % de l'UC suggèrent une légère sur-couverture (intervalles un peu trop larges). L'un comme l'autre est plus utile pour la gestion du risque que l'absence totale d'intervalle.
- Coût de calcul. GBM s'entraîne en quelques secondes ; UC prend ~10–15 s sur cette tranche ; SARIMA est entre les deux. Aucun n'est un goulot d'étranglement.
Esquisse de déploiement
En production, je livrerais l'ensemble, pas seulement le gagnant : GBM pour la prévision ponctuelle, UC pour l'intervalle de prédiction. Opérationnellement :
- FastAPI
GET /forecast?horizon=24hrenvoie moyenne (GBM) + IP 95 % (UC) pour les N prochaines heures. - Cron nocturne ré-entraîne les deux sur les 3 dernières années ; les poids de l'ensemble sont ajustés chaque semaine contre la performance à origine glissante.
- Postgres stocke les instantanés de prévision pour le backtesting ; tableau de bord Grafana suit le MAPE à 7 jours glissants et la couverture des IP.
- Alerte PagerDuty si le MAPE > 7 % pendant 3 jours consécutifs, ou si la couverture observée des IP tombe sous 88 % sur une fenêtre de 30 jours — les deux étant des signes de changement de régime.
Leçons
- « Meilleur » dépend de la métrique. 6 % de MAPE paraît décisif face à 14 % — mais les intervalles calibrés du modèle à espace d'états sont opérationnellement plus utiles pour certains usages aval que la moyenne plus serrée du GBM.
- Les variables construites battent les priors structurels quand les données sont riches. 31 000 heures suffisent largement à GBM pour apprendre la saisonnalité que le modèle structurel doit recevoir explicitement. Avec 5 ans de données mensuelles au lieu de 4 ans de données horaires, ce classement s'inverserait probablement.
- Ne choisissez pas un modèle — choisissez un système de prévision. La moyenne vient du modèle ML, l'intervalle du modèle structurel, le monitoring couvre les deux.